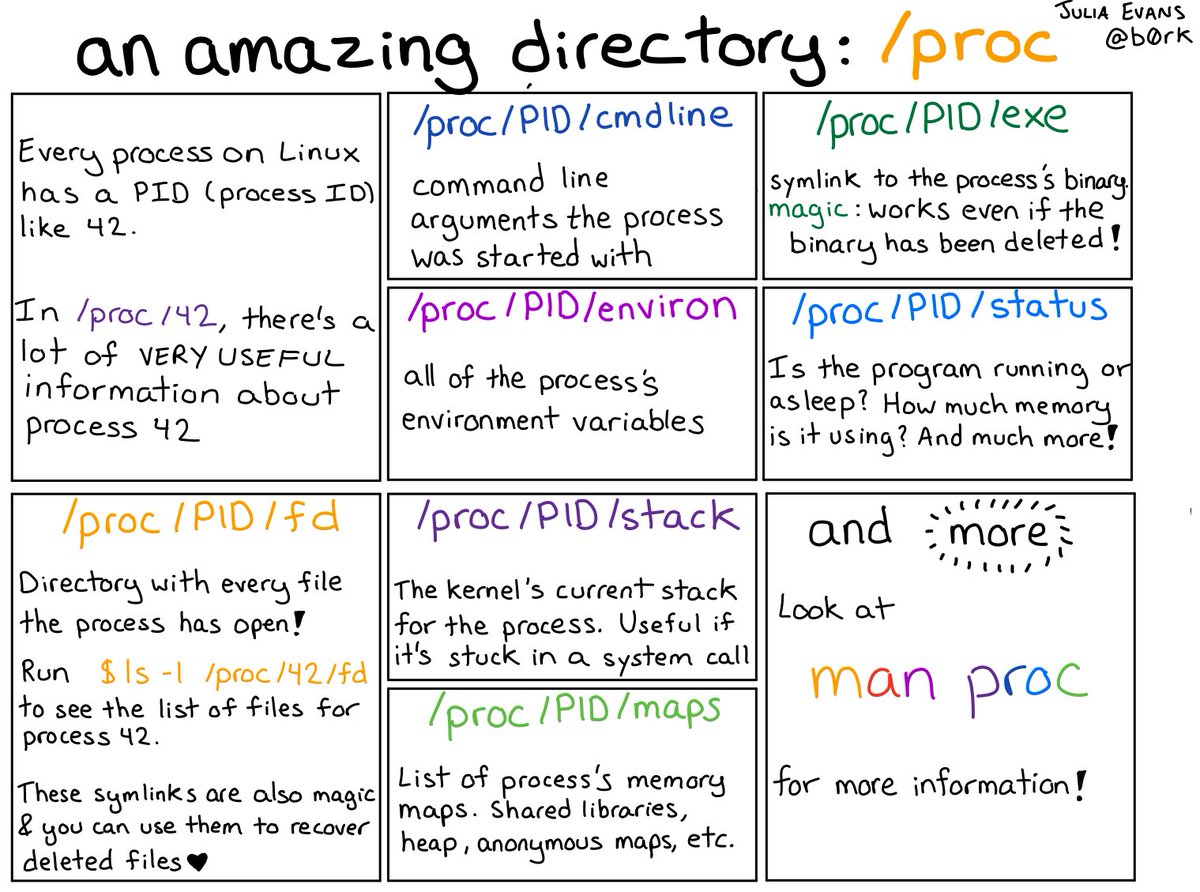
Categories geeking an amazing directory: /proc Post author By kewl Post date April 4, 2018 an amazing directory: /proc Tags Linux, proc
Categories English Glances v1.3.7 released – System monitoring tool for Linux Post author By kewl Post date February 6, 2012 System statistics at a glance: Official site. From Glances v1.3.7 released – System monitoring tool for Linux | The Hacker News THN. Tags Linux, monitoring, system